대용량 JSON

대용량 JSON
이번 프로젝트를 진행하면서 대용량
JSON을 어떻게 처리했는지 간략하게 정리해보려고 합니다.데이터 처리 방식
Request:JSON을 받아서Attribute별로Parsing하여DB에 저장
Response:Attribute별로 조회하여Parsing후Return해결 해야될 문제
Request받은JSON이 저용량 (100MB이하)인 경우 : 사용자가 많아 한번에Request가 많이 들어온 경우Parsing할 때OOM발생Request받은JSON이 대용량 (100MB이상)인 경우 :100MB이상 크기의JSON이 들어온 경우Parsing할 때OOM발생- 조회 시
Parsing할 때OOM발생 및 내부망 문제로 인하여 네트워크 연결 시간이550s로 제한
OOM이 발생하는 이유 분석
JSON을Parsing하는 사이즈가 작아도 보다 많은 양의 메모리를 사용하게 됩니다.Pod가 오류메시지 없이 재시작 되는 경우 :Pod의 메모리가 한계치까지 사용되어 발생합니다. (OOMKilled발생)Java : Heap Out of Memory메시지가 발생하는 경우 :B, KB단위로 전송되는 데이터는 다수의 사용자가 한번에Request를 보내도 처리하는데 문제가 없지만,MB단위에 여러Request가 발생하는 경우에는 메모리가 한계치까지 사용되어 발생합니다.1.
Pod가 재시작 되는 경우
Application Build시Jvm옵션의 메모리 양과Pod의 메모리양이 같거나Application의 메모리가 더 큰 경우, 일정 치 이상의 메모리를 사용하게 되면Pod가 죽고onFailure정책에 따라 재기동되거나 삭제됩니다.해결방안 :
Pod Memory를Application Memory보다 일정량 이상 설정합니다.
※JVM Options중-XX:MinRAMPercentage=(75.0), -XX:MaxRAMPercentage=(75.0)를 사용하게 되면Application이Pod(실제론 물리적 서버의 메모리) 메모리의(75.0)%만 메모리로 설정하게 됩니다.(-Xmx, -Xms 사용 X)2.
JVM에서Heap Out of Memory발생1. 다중의 사용자가 한번에
Request하는 경우 (100MB 미만)
- 사용자가 많아
Json이 여러번Request되는 경우OOM이 발생할 수 있습니다.해결방안 :
Request가 몰리는 경우 서버의 부하를 줄이기 위하여DelayQueue를 사용합니다.
Delay Queue
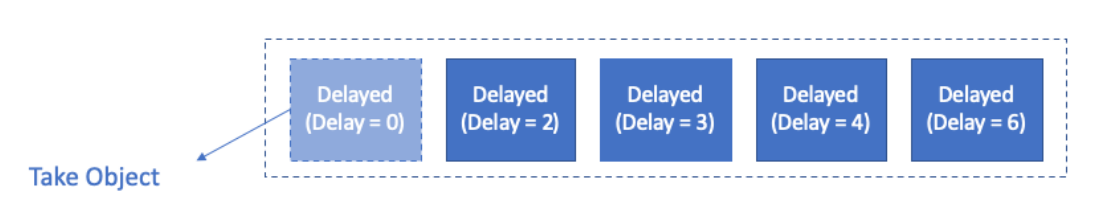
Delay Queue는Element의 딜레이 시간을 기반으로 동작하는Priority Queue입니다.Delay시간을 기준으로 정렬되어 가장 빨리 딜레이 시간이 끝나는 엘리먼트가 큐의 헤드쪽에 위치하게 됩니다.Queue에서 엘리먼트를 꺼낼 때, 딜레이 시간이 지나지 않았다면 소비할 수 없습니다.-
Blocking Queue중 하나인DelayQueue사용법-
DelayedExampleimport java.util.concurrent.Delayed; import java.util.concurrent.TimeUnit; @Getter @Setter @NoArgsConstructor @AllArgsConstructor public class DelayDto implements Delayed { // private final long expTime; @Override public long getDelay(TimeUnit unit) { return unit.convert(expTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS); } @Override public int compareTo(Delayed o) { DelayDto that = (DelayDto) o; int c = Long.compare(expTime, that.expTime); if (c != 0) { return c; } return Integer.compare(System.identityHashCode(this), System.identityHashCode(that)); } }
Delayed를 추상화하여 사용합니다.Delay를 설정하고 우선순위를 계산하는 로직을compareTo메소드에 정의합니다.- 요청이 들어오면
Dto에 담아서Task를DelayQueue에 추가해줍니다.-
SchedulerExampleimport lombok.RequiredArgsConstructor; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.scheduling.annotation.Scheduled; import org.springframework.stereotype.Component; import java.io.IOException; import java.util.concurrent.BlockingQueue; import java.util.concurrent.ExecutionException; @Component @RequiredArgsConstructor public class IssueScheduler { // @Autowired private BlockingQueue<DelayDto> delayQueue; @Scheduled(fixedDelay = 3000) public void process() throws InterruptedException { DelayDto dto = null; while (true) { long maxMem = Runtime.getRuntime().maxMemory() / 1024 / 1024; long totalMem = Runtime.getRuntime().totalMemory() / 1024 / 1024; long freeMem = Runtime.getRuntime().freeMemory() / 1024 / 1024; long usedMem = totalMem - freeMem; double pct = usedMem * 100 / maxMem; if (pct < 85d && delayQueue.size() != 0) { try { file = delayQueue.take(); //...... } catch (InterruptedException | IOException e) { e.printStackTrace(); } catch (ExecutionException e) { throw new RuntimeException(e); } } else { break; } } } }
Java에서 메모리 사용량 확인하는 방법
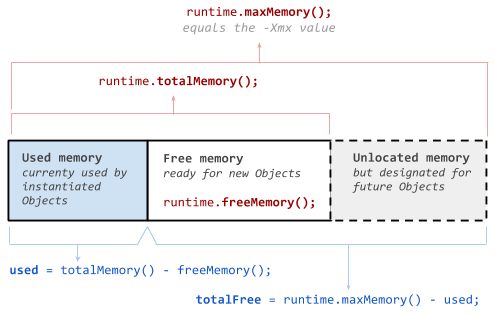
https://stackoverflow.com/questions/3571203/what-are-runtime-getruntime-totalmemory-and-freememory
Scheduler를 사용하여DelayQueue에서Task를 꺼내 소비합니다.- 이 때 현재 메모리 사용량을 구하여
85%이상 사용중이라면Skip합니다.이러한 방식으로
Request가 몰리는 경우를 대비하여메모리 사용량을 확인하고DelayQueue를 이용하여Task를 지연시켜OOM이 발생하는 경우를 방지합니다.2. 대용량 Json을 Issue 하는 경우 (
100MB 이상)
100MB이상의Data를 파싱하는 경우에 한번에 메모리에 올려 놓고 처리하게 되면OOM이 발생할 가능성이 높습니다.Json 파싱으로만 사용하는 서비스가 아니기 때문에OOM이 발생할 경우 서버가 죽게되면, 처리중이던 Task가 사라지거나 사용자의 불편을 초래할 수 있습니다.해결방안 : 서버의 안정성을 위하여
Json 파싱을 위한Pod를 따로 띄워 분리하여 처리합니다. 배치 프로그램을 수행하기 위하여Kubernetes Job을 사용합니다.
Kubernetes Job
Job은 다수의Pod를 지정하고 지정된Pod들을 성공적으로 실행하도록 설정할 수 있습니다. 또한, 별도의 정책을 설정하여Node의 장애나 재부팅이 발생해 정상 실행 되지 않을 경우 새로운Pod를 시작할 수 있습니다.- 즉,
Json을 파싱하여 저장하는 배치 프로그램을 만들어 새로운Job으로 등록하고 작업이 완료되면Application을 종료시켜Job을 완료합니다.
※Data Flow
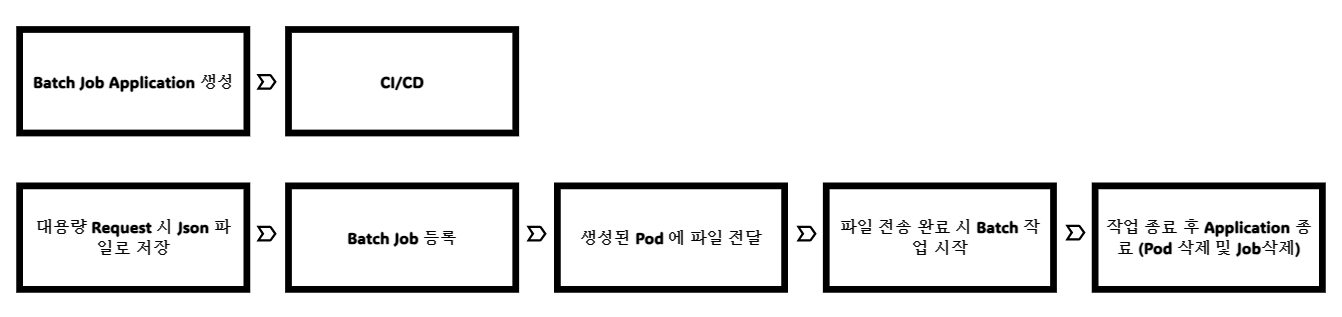
1. Batch Job Application 생성
- 먼저 지정된 위치의 파일을 읽어
Json을Parsing하는Application을 생성합니다.Scheduler를 통해 작업을 진행하며 오류 발생 시 실패Message를Kafka를 통해 전달하고Application을 종료합니다.@Override // 실패시 오류 처리 public void configureTasks(ScheduledTaskRegistrar taskRegistrar) { ThreadPoolTaskScheduler threadPoolTaskScheduler = new ThreadPoolTaskScheduler(); threadPoolTaskScheduler.setPoolSize(2); threadPoolTaskScheduler.setErrorHandler(t -> { String[] splitted = t.getClass().getName().split("\\."); logger.info(">>>>>>> Exception " + splitted[splitted.length - 1]); ... publishKafkaEvent( ..., false, splitted[splitted.length - 1], t.getMessage(), null ); System.exit(0); }); threadPoolTaskScheduler.initialize(); taskRegistrar.setTaskScheduler(threadPoolTaskScheduler); }
- 이 때, 메모리를 최소화하기 위하여 한줄씩 읽어 데이터를 병렬 방식으로 처리하고 저장하는
Steaming방식으로 진행합니다.
- 메모리를 최소화 하는 이유 :
Cluster에 메모리가 한정적이고, 하나의 대용량 파일을 하나의Pod로 처리하기 위해 필요한 최소한의 메모리만 사용해야하므로 사용량을 줄여야합니다.@Scheduled(fixedDelay = 100000L) public void test() { File test = new File("/tmp/data"); if (test.isDirectory() && Objects.requireNonNull(test.listFiles()).length == 2) { // Pod 로 파일 전송 시 전송 완료를 확인 불가능 (다음 단계에서 추가 설명) Arrays.stream(Objects.requireNonNull(test.listFiles())).forEach(file -> { if (file.getName().contains("index.json")) { return; } issueService.readFile(file); // Data 파싱 시작 }); } } ... public void readFile(File file) { // ... ... System.exit(0); }
Scheduler를 통해 파일 전송이 완료되었음을 확인하고 완료되었다면Data Parsing을 시작합니다.- 성공적으로 작업을 마무리했다면
Application을 종료합니다.2.
Pipeline
buildspec.yml
AWS CodeBuild를 사용하므로buildspec.yml을 작성합니다.- 기존 프로그램에서
Batch Job을 실행하기 위해 해당Application의Docker Image ID가 필요합니다.- 최신 버전의
Image ID를 유지하기 위해Build할 때마다ConfigMap을 업데이트합니다.... docker build -f deploy/Dockerfile -t $IMAGE_REPO_NAME:$IMAGE_TAG$BUILD_NO . docker tag $IMAGE_REPO_NAME:$IMAGE_TAG$BUILD_NO {url}/$IMAGE_REPO_NAME:$IMAGE_TAG$BUILD_NO docker push {url}/$IMAGE_REPO_NAME:$IMAGE_TAG$BUILD_NO ... kubectl delete configmap job-image -n $NAMESPACE kubectl create configmap job-image --from-literal=docker.image.name={url}/$IMAGE_REPO_NAME:$IMAGE_TAG$BUILD_NO -n $NAMESPACE ...3. 대용량
Request시Json파일을 서버에 저장
Request로 받은Multipart File을 서버에 저장합니다.4.
Batch Job생성
- 파일 생성이 완료되면 Batch 작업을 위한 Job 을 생성합니다.
implementation("io.fabric8:kubernetes-client:4.12.0")try (KubernetesClient k8s = new DefaultKubernetesClient()) { //2번 에서 저장한 Image ID를 가져오기 위한 ConfigMap 검색 ConfigMap imageConfigMap = k8s.configMaps().inNamespace(nameSpace) .withName("job-image") .get(); //template.metadata ObjectMeta objectMeta = new ObjectMetaBuilder() .addToLabels("app", appName) .build(); //envFrom ConfigMapEnvSource configMapEnvSource = new ConfigMapEnvSourceBuilder() .withName(appName) .build(); EnvFromSource envFromSource = new EnvFromSourceBuilder() .withConfigMapRef(configMapEnvSource) .build(); ConfigMapKeySelector configMapKeySelector = new ConfigMapKeySelectorBuilder() .withName(appName) .withKey("spring.profile") .build(); //env EnvVarSource varFrom = new EnvVarSourceBuilder() .withConfigMapKeyRef(configMapKeySelector) .build(); EnvVar env = new EnvVarBuilder() .withName("SPRING_PROFILES_ACTIVE") .withValueFrom(varFrom) .build(); ResourceRequirements resourceRequirements = new ResourceRequirementsBuilder() .withRequests(Map.of("memory", Quantity.parse("1.5Gi"))) .withLimits(Map.of("memory", Quantity.parse("1.5Gi"))) .build(); //volumeMounts VolumeMount volumeMount = new VolumeMountBuilder() .withName("tz-config") .withMountPath("/etc/localtime") .build(); HostPathVolumeSource hostPathVolumeSource = new HostPathVolumeSourceBuilder() .withNewPath("/usr/share/zoneinfo/Asia/Seoul") .build(); //volume Volume volume = new VolumeBuilder() .withName("tz-config") .withHostPath(hostPathVolumeSource) .build(); Job newJob = new JobBuilder() .withApiVersion("batch/v1") .withNewMetadata() .withName(jobName) .withLabels(Collections.singletonMap("app", jobName)) .endMetadata() .withNewSpec() .withNewTemplate() .withMetadata(objectMeta) .withNewSpec() .withServiceAccount(serviceAccount) .addNewContainer() .withName(jobName) .withImage(imageConfigMap.getData().get("docker.image.name")) // ConfigMap 에 저장되어있는 Image ID 조회 .withResources(resourceRequirements) .withEnv(env) .withEnvFrom(envFromSource) .withVolumeMounts(volumeMount) .endContainer() .addToVolumes(volume) .withRestartPolicy("Never") // 재시작 안함 .endSpec() .endTemplate() .withTtlSecondsAfterFinished(10) .endSpec().build(); k8s.batch().jobs().create(newJob); // Job 생성 Thread.sleep(20000); // Job 생성 대기 Optional<Pod> newPod = k8s.pods().inNamespace(nameSpace).list().getItems().stream().filter(pod -> pod.getMetadata().getName().contains(jobName)).findFirst(); // 생성된 Job 의 Pod 검색 if (newPod.isPresent()) { String podName = newPod.get().getMetadata().getName(); Path downloadToPath = issueFile.toPath(); Path indexPath = indexFile.toPath(); boolean transfer = k8s.pods() .inNamespace(nameSpace) // <- Namespace of pod .withName(podName) // <- Name of pod .file("/tmp/data/" + issueId + "-indexed" + ".json") // <- Path of file inside pod .upload(downloadToPath); if (transfer) { boolean transferIndex = k8s.pods() .inNamespace(nameSpace) // <- Namespace of pod .withName(podName) // <- Name of pod .file("/tmp/data/index.json") // <- Path of file inside pod .upload(indexPath); // File 전송이 완료되면 빈 파일로 완료 확인 if (transferIndex) FileUtils.deleteDirectory(directory); } } catch (InterruptedException e) { throw new RuntimeException(e); }
Job을 생성하는데 필요한 설정 정보를 등록하고Job을 생성합니다.Job을 생성하고나면 완성된 파일을Pod내 특정 위치에File을upload합니다 (kubectl cp메소드 실행)- 파일 전송이 완료되면 빈파일을 같이 하나 더 보내 파일 전송이 완료됐음을 체크합니다. (
Batch Application에서 파일이 전송중임을 확인 불가)
- 해당 방식으로 적용하므로써, 사용자가 많아지면
OOM이 발생하여Pod가 종료되거나 속도가 느려지는 경우가 사라져 안정성이 증가했고 비동기로 여러 작업을 처리하다보니 속도가 빨라지고 메모리를 조금 더 효율적으로 사용할 수 있게 되었습니다.3. 조회 이슈
- 조회 시
Parsing할 때OOM발생
- 대용량 파일을 처리한 데이터를 조회할 때 메모리 사용량을 줄이기 위하여
File을 통해Response를 전달합니다.// Controller @GetMapping public void query(HttpServletResponse httpServletResponse) { httpServletResponse.setContentType("application/octet-stream"); httpServletResponse.setHeader("file", "true"); httpServletResponse.setHeader("Content-Transfer-Encoding", "binary"); httpServletResponse.setHeader("Content-Disposition", "inline;filename=" + fileName + ".json"); httpServletResponse.setStatus(HttpServletResponse.SC_OK); PrintWriter writer = httpServletResponse.getWriter(); ... List<File> listedFiles = Arrays.asList(files); // Parsing 이 완료된 Json 파일들 Partition<File> groupedFiles = Partition.ofSize(listedFiles, splitSize); int groupSize = groupedFiles.size(); for (int i = 0; i < groupSize; i++) { writer.write("["); List<File> splittedFiles = groupedFiles.get(i); int size = splittedFiles.size(); for (int j = 0; j < size; j++) { File issuedFile = splittedFiles.get(j); writer.write(FileUtils.readFileToString(issuedFile, Charset.forName("UTF-8"))); if (0 < size && j < size - 1) { writer.write(","); } } writer.write("]\n"); } writer.flush(); }
- 하지만,
File을 생성하고Parsing후 저장한 뒤 다시 읽어서PrintWriter를 통해Response를 전달하려해도 메모리 사용량이 많아OOM이 발생했습니다.- 또한 내부망을 사용함에 있어 여러가지의
Gateway를 통하다보니 네트워크Session유지 시간이 최대550s로 제한되는 문제가 있었습니다.- 대용량
Json을 파싱하여 파일에 저장하기엔550s는 짧은 시간입니다.- 또한
Data를Parsing하는 시간이 오래걸려 이 것을 비동기로 처리하려는 요구 사항이 있었습니다.해결방안 :
Http Streaming을 사용하여Session이 끊기는 문제와 메모리가 부족한 문제를 한번에 해결했습니다.
Http Streaming
Http기반 스트리밍 또는Http라이브 스트리밍(HLS) 이라고도 하는Http스트리밍은 실시간 으로 데이터를 전달하는 데 사용되는 기술입니다. 이 프로토콜을 사용하면 서버에서 클라이언트 장치로 지속적인 데이터 전송이 가능해집니다.
Spring Http Streaming
Spring에선 다음 3가지의 방식으로Streaming Response방식을 제공합니다.
ResponseBodyEmitterSseEmitterStreamingResponseBody- 이중
StreamingResponseBody는 비정형화된Byte응답을Streaming형태로 전달할 때 사용됩니다.- 이번 프로젝트는
StreamingResponseBody를 통해 비동기 요청 처리를 지원합니다.- 해당 방식의
Application은Servlet Container Thread를 유지하지 않고 응답OutputStream에 직접 데이터를 쓸 수 있습니다.// Controller @GetMapping public StreamingResponseBody query(HttpServletResponse httpServletResponse) { ... ListenableFuture<StreamingResponseBody> responseBody = issueService.asyncQueryFileIssue(query, (int) finalSplitSize); httpServletResponse.setContentType("application/octet-stream"); httpServletResponse.setHeader("file", "true"); httpServletResponse.setHeader("Content-Transfer-Encoding", "binary"); httpServletResponse.setHeader("Content-Disposition", "inline;filename=" + issueId + ".json"); httpServletResponse.setStatus(HttpServletResponse.SC_OK); return responseBody.get(); } // Service @Async public ListenableFuture<StreamingResponseBody> asyncQueryFileIssue(...) { return this.queryFileIssue(query, splitSize); } private ListenableFuture<StreamingResponseBody> queryFileIssue(...) { // ExecutorService executorService = Executors.newFixedThreadPool(10); StreamingResponseBody streamingResponseBody = outputStream -> { BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(outputStream)); AtomicInteger j = new AtomicInteger(0); List<CompletableFuture<Boolean>> futures = new ArrayList<>(); futures.add(CompletableFuture.supplyAsync(() -> { ... (Json Parsing) writer.write(parsed); writer.flush; j.getAndAdd(parsed.size()); ... return true; }, executorService)); List<Boolean> rs = futures.stream().map(CompletableFuture::join).collect(Collectors.toList()); .... writer.close(); executorService.shutdown(); }; return new AsyncResult<>(streamingResponseBody); }
Data Parsing이 완료되는대로BufferedWriter를 사용하여 바로write후flush하여 메모리 사용량을 최소화하였습니다.Http Streaming비동기로 파일을 전송하게 되면 파일이 전송되는 동안은 네트워크Session이 끊어지지 않습니다. 이를 통해,550s문제를 해결하였습니다.그 외에 메모리 부족을 해결하기 위한 노력
- 이번 미션의 가장 중요한 포인트가 메모리 부족 이슈였습니다.
- 위 내용과 별도로 현상 해결을 위해 추가로 진행한 몇가지 부분을 정리해보려고합니다.
1.
Jvm최적화-XX:MinRAMPercentage=75.0 // Memory 제한 (위에 참고) -XX:MaxRAMPercentage=75.0 // Memory 제한 (위에 참고) -XX:MetaspaceSize=1024m -XX:MaxMetaspaceSize=1024m -XX:CompressedClassSpaceSize=512m -XX:+UseStringDeduplication
- Metaspace
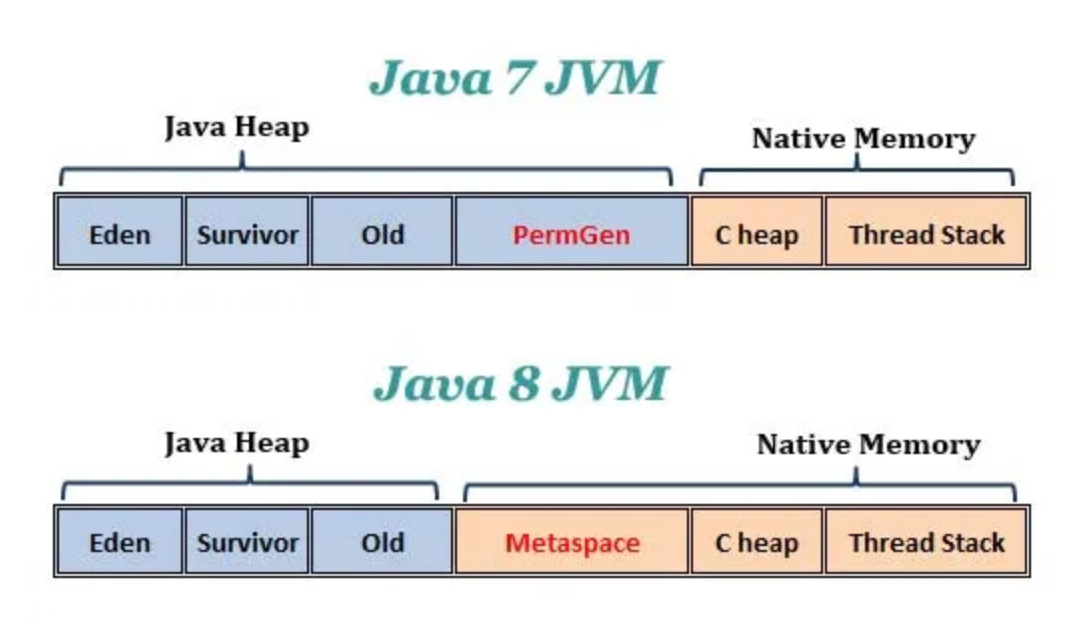
Java7 vs Java8 JVM (from: https://www.programmersought.com/article/4905216600/)
- `Java8` 부터 `JVM` 의 메모리 영역 중 `Permgen(Permanent Generation)` 메모리 영역이 사라지고 `Metaspace` 영역이 생겼습니다. - `Metaspace` 는 간단히 말해 `Java` 의 `Classloader` 가 로드한 `class` 들의 `metadata` 가 저장되는 공간입니다. - `Permgen(Permanent Generation)` 과 `Metaspace` 의 가장 큰 차이는 `Heap` 영역이 아닌 `Native Memory` 영역에 위치합니다. - `Metaspace` 의 `Size` 가 지나치게 늘어나면, 필요한 만큼 기본 값이 늘어나 `Native Memory` 가 부족해지게되면 서버가 죽게됩니다. - `CompressedClassSpaceSize` 는 `Metaspace` 의 중요한 부분인 `Compressed Class Size` 의 가상 사이즈를 지정합니다. - JVM 이 Compressed Class 공간을 확보할 수 없는 경우 오류가 발생할 수 있습니다.
- 무작정 지정하는 것이 아닌
jcmd,jstat등 메모리 덤프를 분석하여 적당한 크기를 지정해주는 것이JVM최적화에 도움이 됩니다.2.
MongoDB 최적화
- 대용량 파일을 조회할 때
MongoDB를 모니터링을 해보니DB에 부하가 많이 일어날수록Memory사용량이 증가하는 것을 확인했습니다.Memory사용량이 증가하고DB부하가 일어날수록 속도가 저하되어 같은Data여도 처리하는 속도가 점점 느려지는 것으로 확인했습니다.- 첫번째로,
Query최적화를 위해MongoDB Index를 설정해주었습니다.- 두번째로,
ReplicaSet을 지정하여Read시에DB부하를 줄였습니다.
MongoDB Replica Set:DB의 데이터들을 여러 서버에 동기화(synchronization)하는 것을 의미합니다.- 여러 서버가 모두 동일한 데이터를 가짐에 따라 하나의 서버가 다운되더라도 제공하는 서비스에 문제가 생기지 않고 운영을 할 수 있다는 장점이 있습니다.
- 각 서버에 데이터 복구/리포팅/백업 역할(용도)을 설정할 수도 있습니다.
Read Preference: 읽기를 할 때 여러가지 설정을 할 수 있습니다.
primary: 모든 읽기 작업은 주DB인Primary만 사용합니다. 이것이Default모드 입니다.primaryPreferred: 주DB에서 읽기 권한을 수행하되, 수행이 불가능한 경우 보조DB에서 읽기 권한 수행합니다.secondary: 보조DB에서만 읽기 권한 수행합니다.secondaryPreferred: 보조DB에서 읽기 권한을 수행하되, 수행이 불가능한 경우 주DB에서 읽기 권한 수행합니다.nearest: network latency 가 가장 낮은DB에서 읽기 권한 수행합니다.
출처: https://www.mongodb.com/docs/manual/core/read-preference// MongoDB Setting 중 MongoClientSettings settings = MongoClientSettings.builder() .credential(credential) .retryWrites(true) .readPreference(ReadPreference.secondaryPreferred()) // ReadPreference 설정 .applyToConnectionPoolSettings(builder -> builder.minSize(10).maxSize(30).maxConnectionIdleTime(5000, TimeUnit.MILLISECONDS)) .applyToClusterSettings(builder -> builder.hosts(Arrays.asList(new ServerAddress(host, port)))) .build();
SecondaryPrefered로 두어Read쿼리의 양이 많아 질 때,Secondary DB에 중점을 두도록 조치하였습니다.- 또한
Spring MongoRepository에서 대용량find시Paging처리를 위해Page<T>객체를 많이 사용하는데, 해당 객체는 호출할 때 마다Count쿼리를 한번씩 실행합니다. 이를 방지하기 위하여Slice<T>를 사용하여 불필요한 쿼리를 실행시키지 않도록 수정했습니다.
- 이번 프로젝트를 진행하면서 성능과 메모리 절약을 위해 정말 다양한 방법을 많이 찾아보고 연구했습니다. 이 외에도 더 많은 방식으로 테스트 해보고 적용시킨 케이스가 여러가지 있지만, 대표적으로 적용시킨 내용을 간략하게 정리해봤습니다.
- 추후 다른 프로젝트를 진행하거나, 비슷한 상황이 발생 했을 때 참고하여 진행하면 좋을 것 같습니다.
yeobang