대용량 데이터 등록
들어가며
현재 진행하는 프로젝트는 monolithic에 sql mapping으로 구성되어 있습니다. 그래서 .xml에 있는 sql을 파싱(Parsing)하고 메타데이터(MetaData)로 만들어서 저장하는 기능이 필요했습니다.
하지만 문제가 있었습니다. mysql에 물리적으로 입력되는 메타데이터의 로우(row)만 한 개 프로젝트에 5만개가 넘어가는 상황이라 클라우드(Cloud) 환경에서 등록시간이 10분이나 소요되는 것이었습니다. 심지어 추후 분석할 프로젝트에 따라서 무한정으로 늘어날 수도 있었습니다. 예를 들어 분석할 프로젝트가 20개라면 단순계산으로 100만개의 메타데이터 등록이 필요합니다. 등록에 대한 시간이 얼만큼 늘어날지 가늠이 되지 않아 데이터 등록 시간을 단축할 필요성을 실감했습니다. 이에 대한 개선 일지를 프로젝트 보안상 변경된 엔티티(Entity)로 예를 들며 설명하겠습니다.
엔티티
@Getter
@Setter
@NoArgsConstructor
@EntitiyImmutable
public class FirstEntity{
//
private String name;
private String id;
}
@Getter
@Setter
@NoArgsConstructor
@EntitiyImmutable
public class SecondEntity{
//
private String name;
private String id;
private String firstEntityId;
}
@Getter
@Setter
@NoArgsConstructor
@EntitiyImmutable
public class ThirdEntity{
//
private String name;
private String id;
private String firstEntityId;
private String secondEntityId;
}
Save를 사용한 기존의 방식
List<String> firstEntityIds = firstEntityCdos.stream().map(firstEntityCdo -> {
String firstEntityId = firstEntityLogic.registerFirstEntity(firstEntityCdo);
secondEntityCdos.forEach(secondEntityCdo -> {
secondEntityCdo.setFirstEntityId(firstEntityId);
String secondEntityId = secondEntityLogic.registersecondEntity(secondEntityCdo);
thirdEntityCdos.forEach(thirdEntityCdo -> {
thirdEntityCdo.setFirstEntityId(firstEntityId);
thirdEntityCdo.setSecondEntityId(secondEntityId);
thirdEntityLogic.registerthirdEntity(thirdEntityCdo);
});
});
return firstEntityId;
}).collect(Collectors.toList());
개선 전에는 FirstEntity를 save하고 등록된 ID를 바탕으로 SecondEntity를 등록하고 SecondEntity의 ID를 바탕으로 ThirdEntity를 등록했습니다. 그래서 FirstEntity의 Id가 1이면 SecondEntity의 Id는 (1.1) (1.2) (1.3) ThirdEntity의 id는 (1.1.1) (1.1.2) (1.2.1) (1.2.2) (1.3.1) (1.3.2) 이런 식으로 등록했습니다. 이 방식은 save 메소드를 너무 많이 사용해 DB와의 커넥션(Connection) 수와 인덱싱(Indexing) 작업이 지나치게 증가하는 문제가 있습니다. 또 다량의 트랙잭션(Transaction) 커밋(Commit)을 수행해야만 하는 문제도 있습니다. 이러한 문제들 때문에 데이터를 등록하는 시간이 지나치게 길어졌습니다.
SaveAll()로 변경
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
@Transactional
@Override
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null!");
List<S> result = new ArrayList<>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}
JpaRepository에서 save와 saveAll을 살펴보면, @Transactional 어노테이션이 붙어서 메서드(Method) 실행 도중에 발생하는 모든 작업을 하나의 트랜잭션으로 처리합니다. save의 경우 메서드 내에서 persist 또는 merge 작업이 수행될 때마다 단일 트랜잭션으로 처리됩니다. 그래서 단일 데이터 등록이 아닌 다량의 데이터 등록이 필요하다면, 수 많은 단일 트랜잭션을 처리해 다량의 불필요한 커넥션과 커밋 작업이 발생합니다.
반면에 saveAll 메소드는 여러 개의 save 메서드 호출을 단일 트랜잭션으로 묶어서 처리하므로 DB와의 커넥션을 불필요하게 초기화하는 작업이 줄어들고 인덱싱 작업과 커밋 작업이 감소해 등록 시간을 줄일 수 있습니다. 이런 이유로 saveAll()을 사용하기로 결정했습니다.
List<ParsingData> parsingDatas = parseMapperXml(path);
List<FirstEntity> firstEntities = new ArrayList<>();
List<SecondEntity> secondEntities = new ArrayList<>();
List<ThirdEntity> thirdEntities = new ArrayList<>();
String firstEntityId = firstEntityLogic.registerFirstEntity(firstEntityCdo);
secondEntityCdos.forEach(secondEntityCdo -> {
secondEntityCdo.setFirstEntityId(firstEntityId);
String secondEntityId = secondEntityLogic.registersecondEntity(secondEntityCdo);
............
하지만 바로 saveAll()을 적용할 수는 없었습니다. 왜냐하면 기존 로직은 엔티티를 등록하고 발행되는 Id를 다음으로 연계해서 그 다음 엔티티를 등록하는 방식이기 때문입니다. 이를 해결하기 위해 채번방식을 채택했습니다. 각 Cdo에 sequence field를 추가하고 Id를 미리 발행해주는 genId() 메소드를 구현했습니다. 해당 메소드를 사용하면 엔티티가 Cdo를 통해 생성될 때 자동으로 Id가 생성됩니다.
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class FirstEntityCdo{
//
private long sequence;
private String name;
private String id;
public String genId() {
//
return sequence;
}
}
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class SecondEntityCdo{
//
private long sequence;
private String name;
private String id;
private String firstEntityId
public String genId() {
//
return firstEntityId + ":" + sequence;
}
}
@Getter
@Setter
@NoArgsConstructor
@EntitiyImmutable
public class SecondEntity{
//
private String name;
private String id;
private String firstEntityId;
public SecondEntity(SecondEntityCdo secondEntityCdo) {
//
BeanUtils.copyProperties(secondEntityCdo, this);
this.id = secondEntityCdo.genId();
}
}
SecondEntity secondEntiy = new SecondEntity(secondEntityCdo);
변경된 로직에서는 빈 List를 만들어서 sequence를 1씩 증가시키면서 EntityCdos에 add해줍니다. 모든 CdoList들이 생성 완료되면 saveAll() 메소드를 활용해서 데이터를 한 트랜잭션으로 등록합니다.
List<SecondEntityCdo> secondEntityCdos = new ArrayList<>();
AtomicInteger secondEntityIndex = new AtomicInteger();
secondEntityCdos.forEach(secondEntityCdo -> {
secondEntityCdo.setSequence(secondEntityIndex.getAndIncrement());
secondEntityCdo.setFirstEntityId(firstEntityId);
secondEntityCdos.add(secondEntityCdo);
...................
SaveAll을 개선하기 위한 노력
SaveAll을 사용했지만, 여전히 극적인 시간 단축은 이루어지지 않았습니다. 그래서 주변에 도움을 요청하고 여러가지 자료를 조사하면서 시간을 줄일 방법을 연구했습니다. 그러다 save에서 JPA의 내장 메소드인 isNew()를 수행하는 부분에서 시간을 단축시킬 수 있다는 것을 알게 되었습니다.
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
isNew()는 엔티티가 영속성 컨텍스트에 저장되어 있는지 검사하는 메소드입니다. 하지만 위에서 변경한 채번 방식의 모든 엔티티는 영속성 컨텍스트에 포함 되어있지 않습니다. 왜냐하면 Id가 매번 새롭게 생성되기 때문입니다. 따라서 isNew()를 통해 영속성 컨텍스트 포함 여부를 검사할 필요가 없습니다.
@Getter
@Setter
@NoArgsConstructor
@Entity
@Table(name = "First_Entity")
public class FirstEntityJpo implements Persistable<String> {
@Id
private String id;
private String name;
private transient boolean creation;
......
@Override
public boolean isNew() {
return this.creation;
}
}
위처럼 JPO를 변경한 후 엔티티들을 saveAll하기 전에,
FirstEntityJpo firstEntityJpo = new FirstEntityJpo(firstEntity);
firstEntityJpo.setCreation(true);
firstEntityJpos.add(firstEntityJpo);
firstEntityMariaRepository.saveAll(firstEntityJpos);
isNew가 항상 true로 나오도록 creation을 true로 변경하고 saveAll()을 진행해서 엔티티에 대한 영속성 컨텍스트 검사를 생략 시켰습니다. 이는 어디까지나 엔티티가 영속성 컨텍스트에 포함되어 있지 않다는 확신이 있기 때문에 가능합니다. 이렇게 해서 시간을 줄였지만, 여전히 소요 시간이 만족스럽지 않았습니다.
배치 인서트 도입
배치 인서트란?
# 단건 insert
INSERT INTO table1 (col1, col2) VALUES (val11, val12);
INSERT INTO table1 (col1, col2) VALUES (val21, val22);
INSERT INTO table1 (col1, col2) VALUES (val31, val32);
# 멀티 insert
INSERT INTO table1 (col1, col2) VALUES
(val11, val12),
(val21, val22),
(val31, val32);
위의 과정처럼 기존의 인서트(Insert)는 단건 인서트 인데 이것을 멀티 인서트 방식으로 변경했습니다. 이렇게 엔티티 여러개를 한 번에 입력하는 것을 배치 인서트라고 합니다. 배치 인서트는 대량의 데이터를 여러 개의 트랜잭션으로 처리하는 단건 인서트와 다르게 일정 크기 만큼을 한 번의 트랜잭션으로 수행하기 때문에 눈에 띄는 성능 향상을 기대할 수 있습니다. 그림1처럼 엔티티 A를 기존 방식으로 Insert하면 1차 캐시에 저장후 영속성 컨텍스트를 플러쉬 해서 DB에 저장합니다.
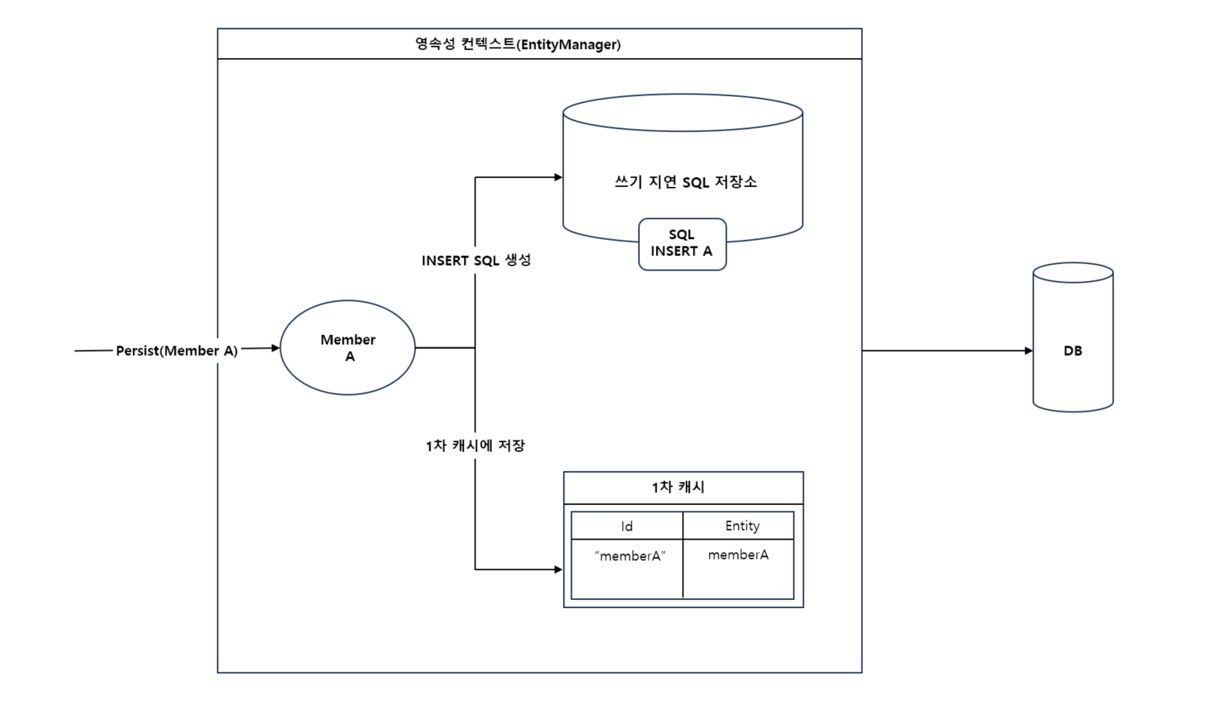
하지만 배치 인서트에서는 그림 2처럼 트랜잭션을 커밋하기 전까지 DB에 엔티티를 저장하지 않고 쓰기 지연 저장소에 INSERT SQL을 저장해둡니다.
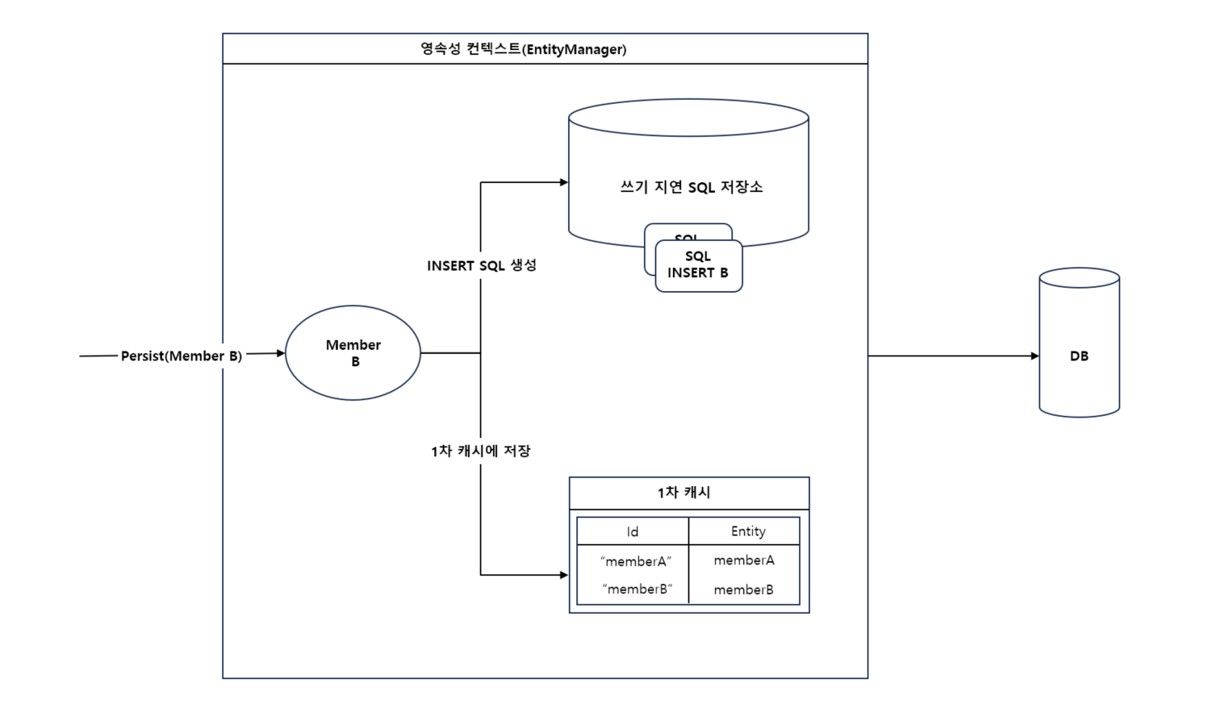
마찬가지로 1차 캐쉬에 엔티티를 계속 쌓으며 저장합니다. 배치 인서트가 지정한 배치 사이즈(BatchSize)에 도달하면, 트랜잭션을 커밋해서 그림 3과 같이 엔티티 매니저가 영속성 컨테스트를 플러쉬 합니다.
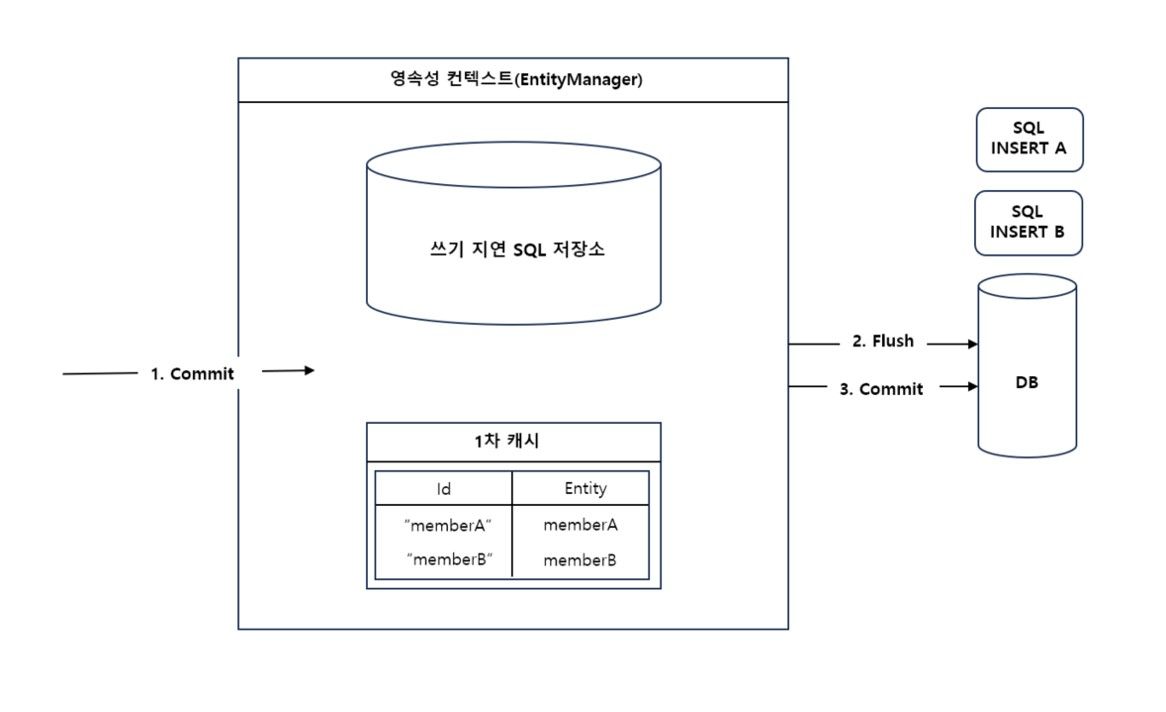
SPRING JPA 배치 인서트 주의사항
@Id
@GeneratedValue(Strategy = GenrationType.IDENTITY)
IDENTITY 전략은 각 엔티티가 개별적으로 DB에서 식별자를 생성하도록 하는 전략인데 스프링 배치는 엔티티의 Key 생성에서 위와 같은 IDENTITY 전략을 사용할 수 없습니다. 배치 인서트는 한 번에 여러개의 엔티티를 DB에 삽입하는 방식이기 때문에 IDENTITY 전략이 불가능합니다. 따라서 TABLE 전략이나 SEQUENCE 전략을 사용해서 여러 개의 엔티티를 일괄 삽입하거나 채번기능을 사용해서 엔티티의 식별자를 미리 생성하는 방식을 채택해야만 합니다. 저는 위에서 언급한 genId()를 이용해서 미리 채번하는 방식을 사용했습니다.배치 인서트를 JPA에서 도입하기 위해서는 application.yml에 배치 관련 설정이 필요합니다.
spring:
jpa:
database: mysql
properties:
hibernate.jdbc.batch_size: 50
hibernate.jdbc.batch_versioned_data: true
hibernate.order_inserts: true
hibernate.order_updates: true
datasource:
url: jdbc:mysql://localhost:3306/entity?rewriteBatchedStatements=true
driver-class-name: com.mysql.cj.jdbc.Driver
위와 같이 설정하면 JpaRepository가 제공하는 SaveAll()은 배치 인서트로 50개 단위로 커밋합니다.
💡 배치 사이즈는 메모리 사용량과 DB 부하를 고려하여 적절하게 설정하는 것이 중요합니다.
너무 크게 설정하면 한 번에 많은 양의 데이터를 메모리에 보관해야 해서 메모리 사용량을 증가시키고 시스템의 가용 메모리를 초과할 수 있습니다. 또 한번에 많은 양의 데이터를 처리해야 하기 때문에 로그 작업과 복구 작업에 소요되는 자원이 증가합니다. 마지막으로 대량의 데이터를 변경하므로 해당 테이블이나 레코드에 대한 잠금과 동시성 문제가 발생할 수 있습니다.
반대로 배치 사이즈가 너무 적으면 배치 인서트 횟수가 증가해 성능 향상이 적고 트랜잭션 오버헤드가 증가할 수 있습니다. 그러므로 적절한 배치 사이즈를 선택하여 DB의 부하를 최소화하고 안정적인 처리를 할 수 있도록 하는 것이 중요합니다. 배치 인서트를 도입 전 9분이 소요되던 기능이 5분으로 대략 50% 향상 되었습니다. 하지만 여전히 속도가 만족스럽지 않아 추가 개선 방식을 고민했습니다.
익스큐터 서비스(ExecutorService)와 컴플리터블 퓨처(CompletableFuture)
다음으로 도입을 고민한 것은 익스큐터 서비스와 JAVA 8의 컴플리터블 퓨처를 활용한 병렬 데이터 등록입니다. 먼저 익스큐터 서비스와 컴플리터블 퓨처에 대해 알아 보았습니다.
익스큐터 서비스
익스큐터 서비스는 java.util.concurrent 패키지에서 제공하는 익스큐터 프레임워크(Executor Framework)의 핵심 인터페이스로 익스큐터(Executor) 인터페이스의 하위 인터페이스입니다. 스레드 풀(ThreadPool)을 지원하여 비동기 작업 요청을 받아서 스레드(Thread)를 실행하고, 결과를 제공합니다. 익스큐터 서비스를 사용해서 작업을 스레드 풀에 할당하면, 스레드풀이 스레드를 관리하여 자원을 최적화하여 사용할 수 있습니다.
익스큐터 프레임워크에서 사용할 익스큐터스(Executors) 클래스의 메서드부터 살펴보겠습니다.
newFixedThreadPool(int nThreads): 지정한 수의 스레드를 가진 고정 크기 스레드 풀을 생성합니다.newCachedThreadPool(): 적절한 수의 스레드(최대 스레드 개수 없음)를 사용하여 스레드 풀을 생성합니다.newSingleThreadExecutor(): 하나의 스레드에서 작업을 순차적으로 처리하는 스레드 풀을 생성합니다.
다음으로 익스큐터 서비스의 스레드 풀 관련 기능들입니다.
submit(): 러너블(Runnable) 또는 콜러블(Callable) 타입의 작업을 스레드 풀에 제출하여 실행합니다.shutdown(): 수행중인 작업을 완료한 후 스레드 풀을 종료합니다.shutdownNow(): 현재 실행중인 작업을 취소하고 스레드 풀을 종료합니다.
컴플리터블 퓨처
컴플리터블 퓨처는 Java 8에서 추가된 비동기 프로그래밍을 위한 클래스입니다. Java 5에서는 퓨처(Future)와 함께 비동기 작업을 처리하는데 퓨처에서 부족했던 기능들이 추가된 버전이라고 할 수 있습니다. Java 5의 퓨처는 외부에서 강제로 완료시킬 수 없고, get 메서드의 타임아웃 설정으로만 완료가 가능했습니다. 하지만 컴플리터블 퓨처는 이름에서 보이듯이 외부에서 완료시킬 수 있습니다. 컴플리터블 퓨처의 기능을 조금 더 자세히 살펴보면,
- 비블로킹 연산 : 퓨처의 경우 get() 메서드를 사용해서 결과를 가져올 때까지 스레드가 블로킹됩니다. 하지만 컴플리터블 퓨처는 비동기 작업의 결과를 콜백(Callback)을 이용해 처리할 수 있어 스레드의 블로킹 없이 결과 처리가 가능합니다.
- 비동기 작업 생성 : 메서드를 사용하여 비동기 작업을 시작하거나(** ForkJoinPool.comonPool : Java의 병렬 작업을 위한 공유된 기본 스레드 풀) 개발자가 원하는 쓰레드풀을 지정하여 작업을 실행이 가능합니다.
- supplyAsync() : supplyAsync() 메서드는 주어진 서플라이어(Supplier)를 비동기적으로 실행하고 결과를 반환합니다. 서플라이어는 매개변수가 없고
CompletableFuture<U>형태로 결과를 반환합니다. - runAsync() : 러너블을 비동기적으로 실행하지만 결과값을 반환하지 않는 함수형 인터페이스입니다. 매개변수는 당연히 없고 반환값도 없습니다.
CompletableFuture<Void>를 반환합니다.
- supplyAsync() : supplyAsync() 메서드는 주어진 서플라이어(Supplier)를 비동기적으로 실행하고 결과를 반환합니다. 서플라이어는 매개변수가 없고
- 함수형 프로그래밍 : 컴플리터블 퓨처는 함수형 프로그래밍을 지원하기 때문에 작업의 결과를 처리하고 다른 작업과 연결시킬 수 있습니다.
- thenApply() : 이 메서드는 완료된 작업의 결과를 다른 작업에 연계하여 처리할 때 사용합니다.
- thenAccept() : 이 메서드는 이전 작업의 결과만을 처리하기 위해 사용합니다.
- thenCompose() : 이 메서드는 이전 작업의 결과물을 사용하여 다른 컴플리터블 퓨처 작업을 수행하는 데 사용됩니다.
데이터 등록 메소드에서 직접 쓰레드풀을 만드는 방식 도입에 대한 고민
처음에는 직접 익스큐터(Executor) 인터페이스의 하위 인터페이스인 익스큐터 서비스를 사용해서 직접 쓰레드풀을 만드는 방식을 도입하려고 했습니다. 아래의 코드처럼 직접 필요한 스레드만큼 생성해서 사용하고 shutdown 시키는 방식입니다.
public void registerFirstEntity(List<FirstEntityCdo> firstEntityCdos) {
//
List<FirstEntity> firstEntities = new ArrayList<>();
ExecutorService executorService = Executors.newFixedThreadPool(10);
int batchSize = sharedTask.genBatchSize(firstEntities.size());
List<CompletableFuture<Void>> futures = new ArrayList<>();
int i = 0;
List<FirstEntity> batch = new ArrayList<>();
for (FirstEntity firstEntity : firstEntities) {
batch.add(firstEntity);
i++;
if (i % batchSize == 0 || i == firstEntities.size()) {
List<FirstEntity> batchCopy = new ArrayList<>(batch);
futures.add(CompletableFuture.runAsync(() ->
firstEntityStore.createAll(batchCopy, batchSize), executorService).exceptionally(ex -> {
ex.printStackTrace();
return null;
}));
batch.clear();
}
}
// wait for all tasks to complete
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
executorService.shutdown();
}
public int roundUp(int num) {
//
int divisor = (int) Math.pow(10, String.valueOf(num).length() - 1);
int quotient = num / divisor;
int remainder = num % divisor;
return remainder > 0 ? (quotient + 1) * divisor : num;
}
public int genBatchSize(int size){
//
int roundUpSize = roundUp(size);
return roundUpSize / 10;
}
익스큐터 서비스를 사용해서 직접 쓰레드풀을 만들면 아래와 같은 장점이 있습니다.
- 더 높은 가용성
- 스프링 스레드풀의 빈 관련 문제를 방지할 수 있습니다. 스프링의 스레드풀 태스크 익스큐터(ThreadPoolTaskExecutor)는 스프링 컨텍스트의 라이프 사이클과 관련이 있어서 스프링 컨텍스트가 종료될 때까지 빈을 유지합니다. 그래서 가끔 스프링 프레임워크의 스레드풀을 사용하는 API에 여러 요청이 동시에 들어오면 빈 관련 문제가 발생하기도 합니다. 스프링 빈의 기본 범위가 싱글톤으로 설정되어 있어 스레드풀 태스크 익스큐터와 같은 빈이 어플리케이션 컨텍스트에 하나의 인스턴스만 생성되어 이런 문제가 발생합니다. 이는 여러 요청이 동시에 들어오면 하나의 빈을 공유하면서 스레드 간 충돌이 발생하기 때문입니다. 이를 위해서 범위를 프로토타입으로 변경하거나 동기화 처리 등의 추가 조치를 취해야만 합니다. 직접 스레드풀을 생성하고 삭제하면 이런 문제에서 벗어나 어플리케이션 전체의 라이프 사이클과 관계없이 사용이 가능합니다.
- 더 높은 유용성
- 직접 스레드풀을 작성하면 메소드에 필요한 로직을 구현할 수 있습니다. 스프링의 스레드풀 태스크 익스큐터는 큐에 적재된 작업이 없을 때도 스레드를 종료하지 않고 회수하지 않습니다. 하지만 직접 스레드풀을 관리하면 로직을 직접 작성했기 때문에 이후로 쓰레드가 불필요하다 판단하면 스레드를 삭제하여 시스템 자원을 효율적으로 사용할 수 있습니다.
- 스레드 생성 비용 절감
- 스프링의 스레드풀 태스크 익스큐터는 내부적으로 스레드를 생성하기 위해 스레드 팩토리(ThreadFactory)를 사용합니다. 하지만 특정 경우에만 스레드를 이용한 빠른 반응성과 높은 성능이 필요한 경우 직접 스레드풀을 만들어 충분한 수의 스레드를 사용하는 것이 비용 절감에 효과적입니다.
- 스레드 개수 제한
- 스프링의 스레드풀은 자동으로 스레드를 생성해주기 때문에 스레드의 개수가 증가할 때 최대 갯수만 제한할 뿐 정확하게 필요한 갯수로 제한 할 수 없습니다. 그러나 직접 스레드풀을 만들면 풀에 사용할 수 있는 스레드 개수를 제한할 수 있습니다. 이는 어플리케이션의 안정성과 예측 가능성을 높이는데 이점이 있습니다.
하지만 저는 아래와 같은 이유로 스프링 프레임워크가 제공하는 쓰레드풀을 사용했습니다.
- 코드 단순화 및 관리 용이성 : 스레드풀 생성, 설정, 제거 등과 관련된 코드를 직접 작성하지 않아도 됩니다.
- 구성 유연성 : 스프링 프레임워크에서 스레드풀 구현에 대한 커스터마이징 기능을 제공합니다. (ex. corePoolSize, maxPoolSize, queueCapacity …
- 안정성 및 성능 : 스프링 프레임워크가 제공하는 스레드풀은 품질 및 성능이 검증된 구현을 사용하므로 안정성과 성능이 높습니다.
- 라이브러리 호환성 : 스프링 프레임워크에 내장된 스레드풀은 스프링 라이브러리와 호환성이 좋습니다.
스프링 프레임워크가 제공하는 @Async 어노테이션을 활용한 병렬 데이터 등록
@Configuration
@EnableAsync
public class AsyncConfig extends AsyncConfigurerSupport {
@Bean(name = "customAsyncExecutor")
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10);
executor.setMaxPoolSize(30);
executor.setQueueCapacity(50);
executor.setThreadNamePrefix("Nextree-ASYNC-");
executor.initialize();
return executor;
}
}
우선 @Async 어노테이션을 사용하기 전에 위의 어싱크 콘피그(AsyncConfig) 설정 클래스를 만들어서 빈(Bean)을 등록해야 합니다. 작성한 어싱크 콘피그 클래스에서 스레드 풀에 항상 10개의 스레드가 존재하도록 설정했습니다. 스레드는 최대 30개까지 사용할 수 있고 작업 대기열의 용량은 50개로 지정했습니다. 제한을 넘기는 작업이 들어오면 신규 작업은 사용할 수 있는 큐가 있을 때 까지 대기합니다.
public void registerFirstEntity(List<FirstEntityCdo> firstEntityCdos) {
//
List<FirstEntity> firstEntities = new ArrayList<>();
int batchSize = sharedTask.genBatchSize(firstEntities.size());
List<CompletableFuture<Void>> futures = new ArrayList<>();
int i = 0;
List<FirstEntity> batch = new ArrayList<>();
for (FirstEntityCdo firstEntityCdo : firstEntityCdos) {
FirstEntity firstEntity = new FirstEntity(firstEntityCdo);
batch.add(firstEntity);
i++;
if (i % batchSize == 0 || i == firstEntityCdos.size()) {
List<FirstEntity> batchCopy = new ArrayList<>(batch);
CompletableFuture<Void> future = firstEntityAction.processFirstEntityBatch(batchCopy, batchSize);
futures.add(future);
batch.clear();
}
}
// wait for all tasks to complete
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]))
.thenApply(v -> futures
.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList())
).join();
}
스프링 쓰레드풀을 사용해서 등록하는 과정입니다.
- 한번에 등록할 개수를 genBatchSize 메소드를 통해 계산합니다.
- 10개의 그룹으로 나눠지도록 메소드를 작성합니다.
- for문을 사용하여 반복적으로 데이터를 처리하며 배치 사이즈에 도달할 때마다 비동기 병렬 등록 메소드를 실행합니다. 생성된 병렬 쓰레드들이 각각 배치 사이즈만큼의 엔티티들을 등록합니다.
- 모든 작업이 완료될 때까지 기다린 후, 필요한 결과를 가공하여 반환합니다.
쓰레드풀 사용에 있어서 후처리
데이터가 기상천외하게 들어오면 컴플리터블 퓨처의 작업 중 에러가 발생할 수 있습니다. 이를 위한 방법에는 여러가지를 떠올릴 수 있습니다. 먼저, 컴플리터블 퓨처의 예외 핸들링을 통해서 예외가 발생한 List<FirstEntity>의 이름을 return 하도록 처리하는 방법이 있습니다. 이렇게 하기 위해서 ThreadResult라는 Vo를 하나 만들었습니다.
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class ThreadResult {
//
private List<String> ids = new ArrayList<>();
private List<String> errorMessages = new ArrayList<>();
}
정상적으로 등록이 되면 List<String> ids에 추가해서 return 하고 예외가 발생했을 때만 에러 메시지를 errorMessages에 추가해서 return 합니다. 그러면 return한 데이터(ThreadResult)를 검증해서 errorMessages의 사이즈(size)가 0보다 클 때( = 에러가 발생했을 때)에 대비하는 로직을 만들어 에러에 대한 후처리를 할 수 있습니다.
public List<ThreadResult> registerFirstEntity(List<FirstEntityCdo> firstEntityCdos) {
//
List<FirstEntity> firstEntities = new ArrayList<>();
int batchSize = sharedTask.genBatchSize(firstEntities.size());
List<ThreadResult> threadResults = new ArrayList<>();
List<CompletableFuture<ThreadResult>> futures = new ArrayList<>();
int i = 0;
List<FirstEntity> batch = new ArrayList<>();
for (FirstEntityCdo firstEntityCdo : firstEntityCdos) {
FirstEntity firstEntity = new FirstEntity(firstEntityCdo);
batch.add(firstEntity);
i++;
if (i % batchSize == 0 || i == firstEntityCdos.size()) {
List<FirstEntity> batchCopy = new ArrayList<>(batch);
CompletableFuture<ThreadResult> future = firstEntityAction.processFirstEntityBatch(batchCopy, batchSize);
futures.add(future);
batch.clear();
}
}
// wait for all tasks to complete
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]))
.thenApply(v -> futures
.stream()
.map(CompletableFuture::join)
.peek(threadResults::add)
.collect(Collectors.toList())
).join();
}
@Async("customAsyncExecutor")
public CompletableFuture<ThreadResult> processFirstEntityBatch(List<FirstEntity> batch, int batchSize) {
ThreadResult threadResult = new ThreadResult();
CompletableFuture<ThreadResult> future = CompletableFuture.supplyAsync(() -> {
try {
List<String> ids = sqlMapCustomStore.createAll(batch, batchSize);
threadResult.getIds().addAll(ids);
}catch (Exception e){
threadResult.getErrorMessages().add(e.getMessage());
}
return threadResult;
}, customAsyncExecutor);
return future;
}
public List<String> createAll(List<FirstEntity> firstEntities, int batchSize) {
//
if (firstEntities == null) {
return null;
}
int i = 0;
List<FirstEntityJpo> firstEntityJpos = new ArrayList<>();
for (FirstEntity firstEntity : firstEntities) {
if (firstEntityRepository.findById(firstEntity.getId()).isPresent()) {
throw new IllegalArgumentException("firstEntity already exists. " + firstEntity.getId());
}
FirstEntityJpo firstEntityJpo = new FirstEntityJpo(firstEntity);
firstEntityJpo.setCreation(true);
firstEntityJpos.add(firstEntityJpo);
i++;
if (i % batchSize == 0 || i == firstEntities.size()) {
firstEntityRepository.saveAll(firstEntityJpos);
firstEntityJpos.clear();
}
}
List<String> ids = firstEntities.stream().map(FirstEntity::getId).collect(Collectors.toList());
return ids;
}
또는 아래처럼 모든 데이터 등록 작업 중 하나라도 예외가 발생하면, 프론트 엔드로 실패 메시지를 전송 시키는 방법도 있습니다. 사용자가 등록 과정의 실패를 인지 후 해당 원인이 무엇인지 파악하고 직접 데이터를 재가공해서 후처리를 진행하도록 유도하는 방법입니다. 물론 이러한 방식도 어떤 데이터가 실패를 유발했는지 알아야 하기 때문에 에러 메시지를 전달할 필요가 있습니다.
public List<String> registerEntities(String projectId) {
//
try {
List<String> strings = registerEntityProcess(projectId);
return strings;
}catch (RuntimeException e){
sendWebSocketErrorMessage(
WebSocketStatus.Error,
"Entity",
"FirstEntity",
e,
"FirstEntity 등록 과정에서 에러가 발생했습니다.");
sendWebSocketErrorMessage(
WebSocketStatus.Error,
"Entity",
"SecondEntity",
e,
"SecondEntity 등록 과정에서 에러가 발생했습니다.");
sendWebSocketErrorMessage(
WebSocketStatus.Error,
"Entity",
"ThirdEntity",
e,
"ThirdEntity 등록 과정에서 에러가 발생했습니다.");
throw e;
}
}
private void sendWebSocketErrorMessage(WebSocketStatus status, String entityName, Exception exception, String errorMessage) {
//
List<String> dataNames = extractDataNamesFromException(exception);
sendWebSocketMessage(status, entityName, dataNames);
webSocketMessage.sendMessage(status, "Entity", entityName, errorMessage);
}
대용량 데이터 등록 개선 결과표
등록한 엔티티 개수 : 약 70000개
| 회차 | 방식 | Cloud 시간 | local 시간 |
|---|---|---|---|
| 1차 | saveAll | 9분 40초 | 5분 40초 |
| 2차 | saveAll 개선 | 9분 | 5분 10초 |
| 3차 | BatchInsert | 5분 | 3분 |
| 4차 | 멀티 쓰레드 | 1분 40초 | 1분 30초 |
결과적으로 대용량 데이터 등록 시간에 오차가 있지만, 2분 내로 줄였습니다.
대용량 데이터 등록에 대한 고민을 마치면서..
처음 기능을 개발하고 다른 분들에게 의견을 구했을 때 위와 같은 의견을 들었습니다. 개인적으로 토이 프로젝트를 구현할 때는 한번도 생각해보지 못했던 의견이었습니다. 제가 사용자라고 가정하니 등록에 1분 이상만 걸려도 사용을 꺼릴 것 같았습니다. 그러한 생각에서 ‘대용량 데이터 등록에 대한 고민’이 시작되었습니다. 비록 엔티티를 물리적으로 등록해야 하는 수가 5만개를 넘어가면서 1분 이내로 줄이지는 못했지만, 처음에 비해서는 많이 줄일 수 있었습니다. 더 나은 방법을 찾는 과정에서 수 많은 에러들이 매번 나타나서 주변 선배님들에게 질문하고 귀찮게 해드린게 한 두 번이 아닙니다. 그런데도 귀찮아 하지 않으시고 친절하게 알려주신 많은 분들에게 감사합니다. 새로운 시도를 도입하고 실패하고 다시 조금 나아가는 과정을 거치면서 산 하나를 오르락 내리락 했습니다. 그 결과로, 야트막한 산 하나를 넘어갈 수 있어서 기쁩니다. 주니어 개발자의 오류 해결 일지가 다른분들께 조금이나마 도움이 되었으면 합니다. 긴 글 읽어주셔서 감사합니다.