스프링 대용량 트래픽 처리


#0. 대용량 트래픽 처리의 필요성
- 웹 서비스를 다루는데 있어 트래픽을 처리하는 구조를 설계하고 적용하는 것은 개발자의 필수 역량이다. 특히 서비스의 규모가 커질 수록 개발자가 의도한 대로 프로그램이 작동하지 않는 경우가 발생한다. 아무리 뛰어난 성능을 가진 서버라고 해도 모든 트래픽을 감당할 수는 없으므로 서비스의 안정적인 구동과 만족도 높은 고객 경험을 제공하기 위해 대용량 트래픽을 다루는 기술을 학습하고 대비해야 한다.
#1. 대용량 트래픽 장애의 발생 원인
- 사용자가 많아질 수록 서버에는 많은 HTTP request 가 발생한다. Request 가 많아졌다는 것은 트래픽이 높아졌다는 의미이다. Request 는 Queue 를 통하여 Thread pool 에 할당되게 되는데 Thread pool size 를 초과하는 요청은 큐에서 대기한다. Thread 의 개수는 무한하지 않으므로 시스템에 할당된 성능에 따라 제한된다. 따라서 Thread pool size 를 초과하는 대량의 트래픽이 지속적으로 발생하면 서버의 지연시간은 기하급수적으로 증가하게 된다. 이와 같은 현상을 Thread pool hell 이라 한다.
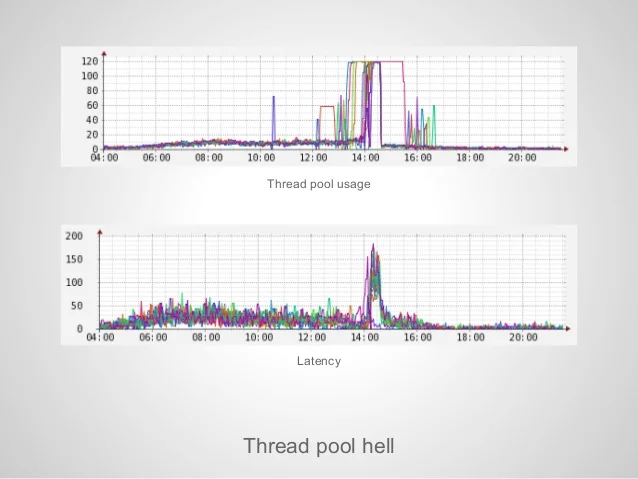
-
트래픽의 종류는 크게 세가지 종류로 나눠진다.
-
Unicast
Unicast는 일대일 통신(송신기 1대 - 수신기 1대)
PC가 서버로 파일을 전송할 때 두 장치는 유니캐스트 통신을 사용한다.
-
Multicast
Multicast는 일대다 통신(송신기 1대 - 수신기 여러대)
비디오 스트리밍을 예로 들어, 비디오 소스(송신기)는 PC, 태블릿, 스마트폰 등으로 비디오 스트림을 전송한다.
Multicast 트래픽은 많은 자치에 보낼 수 있지만, 네트워크 내 모든 장치로 보낼 수는 없다. 패킷을 네트워크의 일부 선택된 스테이션에만 보낸다. 이메일 전송, 멀티미디어 전송 등이 있다. UDP 전송 프로토콜을 사용한다.
데이터를 여러 사람에게 보내려면 유니캐스트를 사용할 때 많은 대역폭을 낭비하지만 멀티캐스팅은 대역폭을 보다 효율적으로 활용한다.
대규모 네트워크에서는 멀티캐스트가 제대로 수행되지 않는다.
-
Broadcast
Broadcast는 일대 전부 통신(송신기 1대 - 수신기 전부)
예를 들어, 모든 스테이션이 수신하고 처리할 수 있도록 하는 네트워크 주소가 있다. Layer 2 에서는 MAC 주소 FF:FF:FF:FF:FF:FF이고, Layer 3 에서는 IP주소 255.255.255.255이다.
이를 통해 하나의 컴퓨팅 장치가 네트워크에 있는 다른 컴퓨터를 검색할 수 있다.
-
-
트래픽은 Input 과 Output 의 상호작용이다. 동일한 Input 을 받더라도 Input 의 종류, 서버의 성능/개수, 처리코드 등에 따라 프로그램은 정상적으로 구동할 수도, 장애가 발생할 수도 있다. 다양한 상황에서 Input 을 받고 안정적으로 Output 을 산출하기 위해 발전한 I/O 처리 모델들을 알아보자.
#2. I/O(Input-Output)
- 트래픽은 쉽게 말하면 Input 에 따른 Output 을 주고받는 과정이다. I/O 는 진행 방식에 따라 크게 3가지로 나눌 수 있다.
- Blocking I/O
- Spring MVC 와 RDBMS 가 채택하고 있는 가장 기본적인 모델이다. 이 방식은 Request 이후 Response 를 받기 전까지 Application 이 Block 된다. 대부분의 Java 프로젝트 들이 Blocking 방식으로 설계가 되어 있지만, 각 Input 마다 새로운 Thread 가 할당되므로 속도의 저하를 체감할 수 없다. 하지만 위에서 설명한 대로 Input의 개수가 Thread pool을 초과하게 되면 Thread 전환이 불가능하게 되므로 시스템 성능이 급격히 저하된다. 또한 I/O 마다 Thread 를 할당해야 하는 Context switching 비용이 발생하므로 시스템 효율성을 보장하지 못한다.
- Synchronous Non-Blocking I/O
- Request 이후 바로 Return 되고 다른 작업을 수행하면서 Response 의 준비 여부를 체크해 Response 를 처리한다. Response 의 주기적 체크 방식을 Polling 이라 하는데 작업이 완료되기 전까지 지속적으로 호출하는 리소스를 사용해야 하므로 시스템 효율성이 떨어질 수 있다.
- Asynchronous Non-blocking I/O
- Synchronous Non-Blocking I/O 방식과 마찬가지로 Request 이후 즉시 Return 된다. 하지만 Polling 방식과 다르게 Response 이벤트가 발생하거나 미리 등록해 놓은 Callback 을 통해 작업을 완료하므로 I/O 과정에서 불필요한 대기 시간과 리소스 사용을 줄일 수 있다.
- Blocking I/O
#3. 대용량 트래픽을 처리하는 방법
- 대용량 트래픽을 처리하는 방법은 어플리케이션의 구조와 설계 방식, 시스템 환경에 따라 고정적이지 않고 다양한 방식을 적용할 수 있다. 서비스 별로 적용할 수 있는 해결책 중 Spring Framework Reactive Stack 적용, MSA 환경에서 BFF 패턴 (WebFlux) 적용, Scale-out 적용 후 세션 일관성 유지, 캐싱을 통한 DB부하 분담 에 대해 알아보려 한다.
-
Spring Framework Reactive Stack
-
위에서 언급한 Asynchronous Non-blocking I/O 모델의 대표적인 예는 Spring Framework Reactive Stack 이다. Reactive Stack 에서 Non-blocking I/O 를 수행하기 위해 WebFlux 프레임 워크를 사용한다. WebFlux 구조는 사용자들의 Request 를 Event Loop 를 통해 처리하며 하나의 Thread 로 하나의 작업을 처리하던 기존의 Spring MVC 방식과 다르게 하나의 Thread 가 여러 작업을 처리 가능하다. WebFlux 의 성능을 최대로 활용하기 위해서 작업을 처리하는 사이클 전반적 이벤트 처리는 Non-blocking 기반으로 구축되어야 한다. 예를 들어 WebFlux 를 활용해 Non-blocking 방식으로 Request 를 보내더라도 접근한 데이터베이스에서 Non-blocking 을 지원하지 않는다면 데이터베이스 접근 인터페이스에서 Blocking 이 발생하게 되므로 Reactive stack 을 활용할 시 Mongo, Cassandra, Redis, Couchbase 등 Non-blocking 을 지원하는 DBMS 를 채택해야 한다. Blocking I/O 와 Non-blocking I/O 의 코드를 간단하게 비교해 보자.
-
Blocking I/O
@Test public void blocking() { final RestTemplate restTemplate = new RestTemplate(); for (int i = 0; i < 3; i++) { // spring 내장 클래스인 restTemplate 을 활용한 api final ResponseEntity<String> response = restTemplate.exchange(THREE_SECOND_URL, HttpMethod.GET, HttpEntity.EMPTY, String.class); assertThat(response.getBody()).contains("success"); } } // Blocking I/O 방식으로 api 호출 시 마다 blocking 발생 -
Non-blocking I/O
@Test public void nonBlocking() throws InterruptedException { for (int i = 0; i < LOOP_COUNT; i++) { // nonBlocking 방식인 webFlux 의 webClient 를 활용한 api this.webClient .get() .uri(THREE_SECOND_URL) .retrieve() .bodyToMono(String.class) .subscribe(it -> { count.countDown(); System.out.println(it); }); } count.await(10, TimeUnit.SECONDS); } // LOOP_COUNT 를 증가시키더라도 결과 반환까지 시간이 크게 증가하지 않는다.
-
-
MSA 환경에서 BFF(Backend For Frontend) 패턴
- BFF 활용 구조도
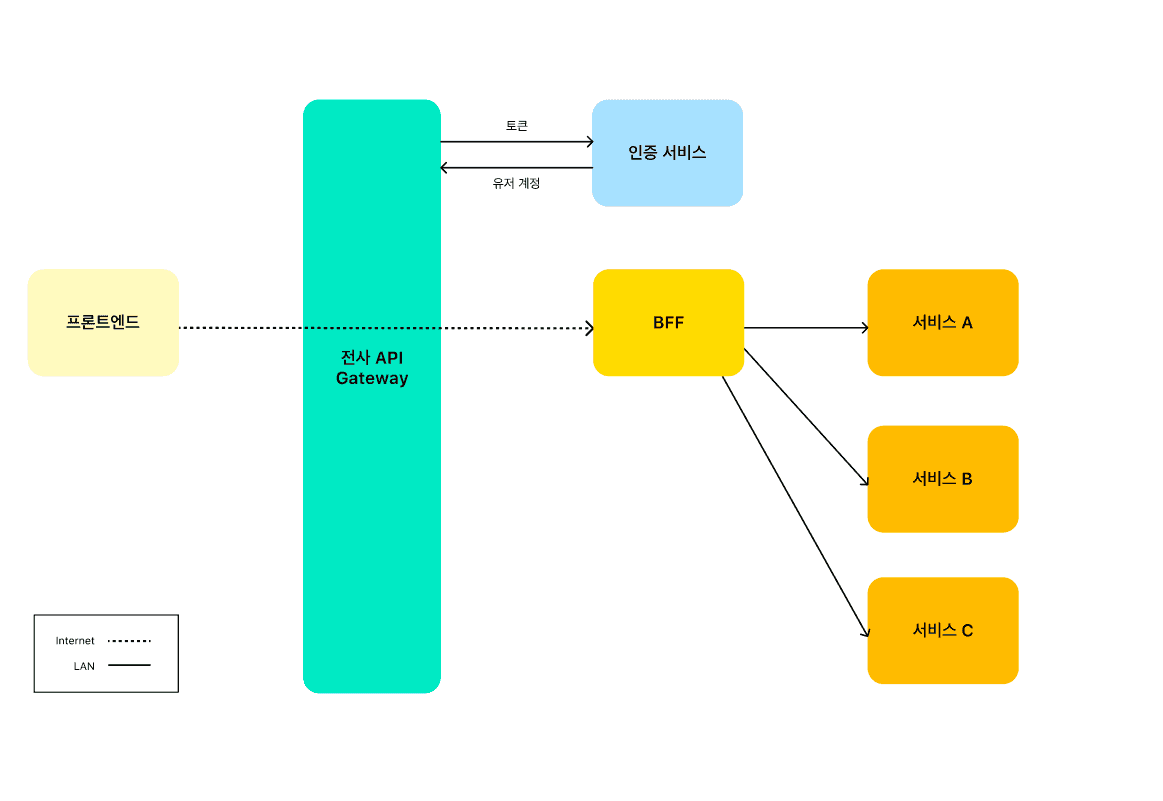
- MSA 구조를 활용하면 서버를 분산시켜 서비스를 안정적으로 구동하고 유지 보수를 용이하게 할 수 있다는 장점이 있다. 하지만 MSA 프로젝트에서는 프론트앤드와 통신의 효율성을 고려한 설계가 필요한데 그 중 대표적으로 API 를 통합적으로 관리해 줄 수 있는 BFF (Backend For Frontend)가 있다. 프론트엔드에서는 한번의 클릭만으로 MSA 의 여러 MS 에 접근해야 하는 경우가 발생한다. 이 때마다 각 MS 에 호출을 발생시켜야 하며 호출 마다 인증 절차를 거친 후 Response 를 받아와야 하는 비효율이 발생하게 된다. BFF 를 활용한다면 프론트엔드는 각 서비스에 직접 통신을 할 필요 없이 BFF에 통신을 위임하게 된다. 프론트엔드와 BFF 가 통신을 하고 BFF 는 프론트엔드로부터 받은 Request 를 분리해 각 서비스에 Request 를 보낸다. BFF 는 각 서비스로부터 받은 Response 를 조합해 프론트엔드로 Response 하게 되면 통신은 완료된다. BFF 의 효율성을 극대화 하기 위해서는 위에서 설명한 WebFlux 와 같은 Asynchronous Non-blocking 을 지원하는 프레임워크를 사용하는 것이 좋다. MSA 프로젝트를 설계한다면 프론트앤드가 각 MS 와 직접 통신을 하면서 발생하는 중복 인증절차를 줄이고 API 호출을 위임해 비동기 방식으로 분산된 데이터를 수집할 수 있는 BFF 의 활용을 고려해 볼만 하다.
- Scale-out 적용 후 세션 일관성 유지
- 서버의 리소스의 부족 문제는 Scale-up 과 Scale-out 방식으로 해결 가능하다. Scale-up 은 서버 한대의 성능을 높여 작업 처리 능력을 높이는 방법이며, Scale-out 은 여러대의 서버를 구축하여 서버 한대가 처리하는 용량을 줄임으로써 전체적인 성능을 증가시키는 방법이다. 그 중 Scale-out 은 한대가 부담해야 했던 서버 장애 리스크를 줄일 수 있고 가성비적 측면에서도 비교우위에 있어 Scale-up 보다 효율적인 리소스 부족 해결방식이다. 하지만 Scale-out 을 적용하게 되면 세션 불일치 문제가 발생한다. 세션 불일치를 해결할 수 있는 방법으로는 Sticky session, Session-clustering, In-memory DB 등이 있다.
- Sticky session
서버마다 고정적인 세션을 관리하는 방식이다. 특정 서버에 트래픽이 집중될 될 경우 서버에 과부하가 발생할 수 있으며, 서버 장애시 해당 서버의 세션이 소실될 가능성이 있다. - Session-clustering
여러 서버가 세션을 하나의 클러스터로 묶어 관리하는 방식이다. 특정 서버에 장애가 발생하더라도 세션이 소실되지 않지만, 서버를 구동할때마다 세션 클러스터링을 새로 설정해야 하며 Was 마다 클러스터링 설정이 다르므로 번거롭다는 단점이 있다. - In-memory DB
- Sticky session
- 서버의 리소스의 부족 문제는 Scale-up 과 Scale-out 방식으로 해결 가능하다. Scale-up 은 서버 한대의 성능을 높여 작업 처리 능력을 높이는 방법이며, Scale-out 은 여러대의 서버를 구축하여 서버 한대가 처리하는 용량을 줄임으로써 전체적인 성능을 증가시키는 방법이다. 그 중 Scale-out 은 한대가 부담해야 했던 서버 장애 리스크를 줄일 수 있고 가성비적 측면에서도 비교우위에 있어 Scale-up 보다 효율적인 리소스 부족 해결방식이다. 하지만 Scale-out 을 적용하게 되면 세션 불일치 문제가 발생한다. 세션 불일치를 해결할 수 있는 방법으로는 Sticky session, Session-clustering, In-memory DB 등이 있다.
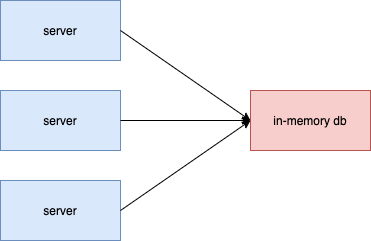
- 디스크가 아닌 외부 메모리에 데이터를 저장하는 데이터 베이스를 의미한다. 디스크가 아닌 메모리에 저장하기 때문에 세션정보와 같은 임시 데이터를 저장하는 것이 바람직하다. 서버들이 동일한 인메모리 데이터베이스를 바라보기 때문에 서버 추가가 용이하며 속도도 빠른 Redis, Memcached 와 같은 인메모리 데이터 베이스를 사용해 세션 일관성을 유지하는 것을 고려해 볼만 하다.
- 캐싱을 통한 DB 부하 분담
-
서비스에서 공통된 데이터를 지속적으로 사용자에게 제공하는 경우가 있다. 사용자에게 필요한 공통된 정보를 제공하기 위해 매번 DB 에 접근해 데이터를 조회하는 것은 데이터 베이스 서버의 리소스를 낭비하는 것이며 서버 전체 성능에도 악영향을 줄 수 있다. 이 때 자주 사용 되는 데이터를 임시로 캐시 서버에 저장해 제공하는 방법을 고려해야 한다. 캐시는 로컬 캐시(Local Cache) 와 글로벌 캐시(Globa Cache) 로 구분되는데 Spring MSA 방식에서는 글로벌 캐시를 통해 다중 서버에서 동일한 데이터를 전달 받을 수 있도록 Redis 를 적용할 수 있다. Spring 에서 Redis 인메모리 캐싱을 활용하기 위한 간단한 예제 코드를 살펴보자.
@EnableCaching // CacheManager 인터페이스를 구현한 Bean 등록 @SpringBootApplication public class AddressApplication{ public static void main(String[] args){ SpringApplication.run(AddressApplication.class, args); } } // SpringCacheManager 설정 @Configuration public class RedisConfig{ @Bean public RedisConnectionFactory connectionFactory(){ return new LettuceConnectionFactory(); } @Bean public RedisTemplate<Object, Object> redisTemplate() { RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>(); redisTemplate.setConnectionFactory(connectionFactory()); redisTemplate.setKeySerializer(new StringRedisSerializer()); redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer()); return redisTemplate; } @Bean public CacheManager redisCacheManager() { RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration .defaultCacheConfig() .serializeKeysWith(RedisSerializationContext .SerializationPair .fromSerializer(new StringRedisSerializer())) .serializeValuesWith(RedisSerializationContext .SerializationPair .fromSerializer(new GenericJackson2JsonRedisSerializer())) .entryTtl(Duration.ofMinutes(5L)); RedisCacheManager cacheManager = RedisCacheManager .RedisCacheManagerBuilder .fromConnectionFactory(connectionFactory()) .cacheDefaults(redisCacheConfiguration) .build(); return cacheManager; } } // 캐시 등록 및 조회 service public class addressService{ @Cacheable(value = "address.region", key = "#region", cacheManager = "redisCacheManager") public List<Address> searchByRegion(String region) { return addressLogic.searchByRegion(region); } @Scheduled(fixedDelay = 300000L) // 5분마다 캐시 갱신 @Cacheable(value = "address.total", key = "total") public List<Address> searchTotal(){ return addressLogic.searchTotal(); } }
-
#4. 정리하며
- 어플리케이션을 설계할 때 프로세스 전반에 발생할 수 있는 이슈 사항을 사전에 파악하고 대비해야 하지만, 그 대응 방법은 고정된 것이 아니라 어플리케이션이 구동되는 환경, 설계 구조, 클라이언트, 요구사항에 따라 다양한 방식이 적용될 수 있다. 위에서 살펴본 대용량 트래픽 처리에 관한 대응 방법은 서버에서 할 수 있는 대응 방법들 중 일부일 것이다. 따라서 서비스 개발자는 끊임없는 학습을 통해 여러 상황에서 발생할 수 있는 이슈에 대해 다양한 해결책을 살펴보고 적절히 대응할 수 있어야 한다.
참조
https://www.youtube.com/watch?v=qzHjK1-07fI
https://seohoon-dev.tistory.com/4